
CROSSDat is a platform with unified access to SWEET and energy related (research) data, irrespective of where it is stored and curated. It provides a platform for aggregation of SWEET and energy related data that increases the efficiency of data access and contributes to the exchange, outreach and development of SWEET-related research.
The main distinguishing feature of CROSSDat is that it is both a database and a metabase that presents data consumers with a platform with aggregated energy data:
- The metabase (database of metadata) automatically understands and harvests metadata from existing external data management systems and databases and presents it. This allows data producers, which already use existing databases, to use CROSSDat without duplicating efforts.
- The database allows researchers from SWEET consortia and beyond to host and directly publish energy-related data (with its accompanying metadata).
CROSSDat Structure
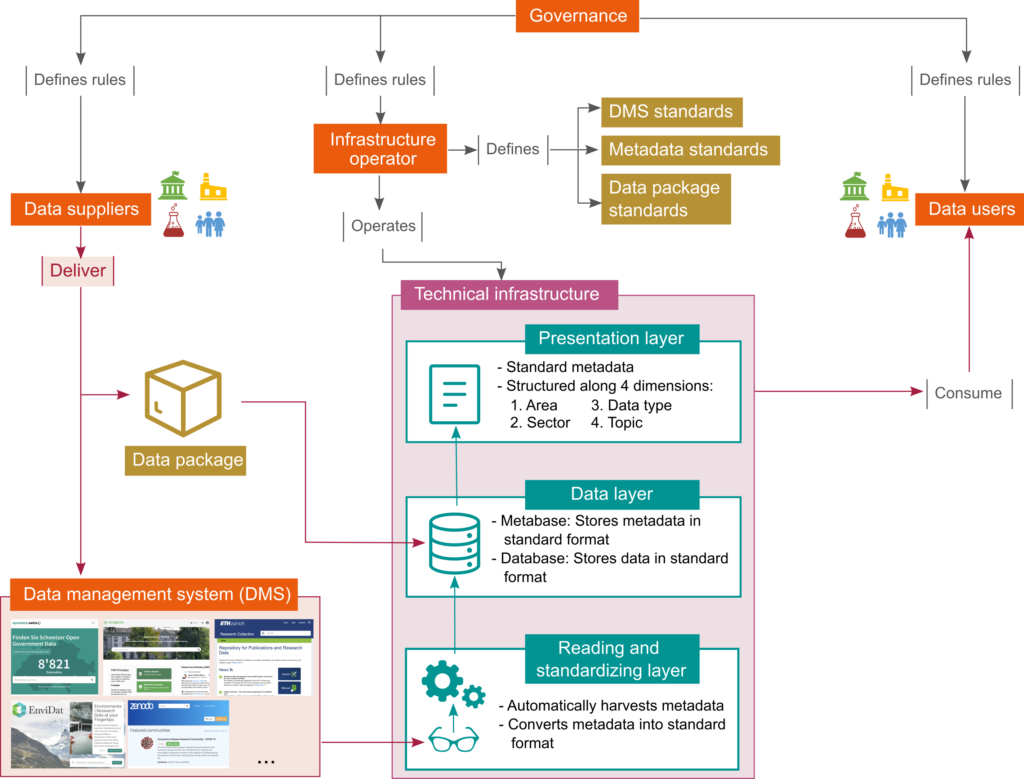
- Data providers deliver data either using their preferred data management system or upload their data to the CROSSDat database.
- The infrastructure operator (1) defines standards for data management systems, metadata and data packages; and (2) operates the technical infrastructure.
- The technical infrastructure includes three layers: (1) Reading and standardizing: Automatically harvest metadata and converts it to the standards; (2) Data layer that stores metadata and data; and (3) Presentation layer that is the interface with the data consumers.
- Finally, on top of all these actors, a governance (still under construction) decides the rights and duties of data providers and data consumers.
Principles
- Unified data access: The main objective of CROSSdat is to provide a platform with unified access to SWEET and energy related research data, irrespective of where it is stored and curated.
- Distributed research data management: Research data management is organized in a decentralized manner where the responsibility to curate research data remains with the experts and the original data providers.
- Findable (and traceable): Datapackages are assigned a unique identifier with a certain standard (e.g. DOI from DataCite) or contain an unique identifier; Data is described with rich metadata; Traceable: Different versions should be clearly timestamped and easy to find.
- Accessible: Data can be retrieved by their identifier using a standardized communications protocol; No login should be needed to have access to the data. However, data that is not public yet can have restricted access.
- Interoperable: The datapackages use formal, accessible, shared, and broadly applicable language for knowledge representation (frictionless); The platform is able to understand, parse and harvest external sources and present them
- Reusable: Data includes a clear and accessible data usage license